A few weeks ago, Facebook1 published a blog post called Sapling: Source control that’s user-friendly and scalable that I read with great interest.
Source control is an interest of mine.
It’s this absolutely critical tool in our software lives, but it’s got this ruthless learning curve that leads to most people carving out a small handful of commands they feel confident using, and never straying outside of those.
People keep trying to figure out ways to make it easier to use – I’m thinking of things like Tower, GitHub Desktop, and Visual Studio Code’s Source Control – and they’re actually pretty great.
I’m particularly impressed with the Visual Studio Code one, because it embraces the exact same terminology that you find when using the git command line interface2, but it organizes that information and presents it all in very usable ways (the conflict resolution tooling in particular is night and day better than anything I’ve used before).
Plus, it’s always fun to hear about people dealing with devex scaling issues. They’ve got so many people over there writing so much code that they have to have huge internal teams to make tools for the rest of them to use just to keep up. That’s nuts. Godspeed to ‘em.
Enter sapling, their new CLI tool, which seems to be a new client for git repositories.
That is, you can bring your own git repository, but instead of using the git CLI or any of the graphic clients I mentioned above, you use their alternative CLI, which you invoke on the command line with sl.
Here’s the thing… “sapling” is a great project name3 and sl is a great name for a command.
There’s only one problem, and it’s a showstopper: sl is taken!
Here’s what I see when I run sl in my terminal:
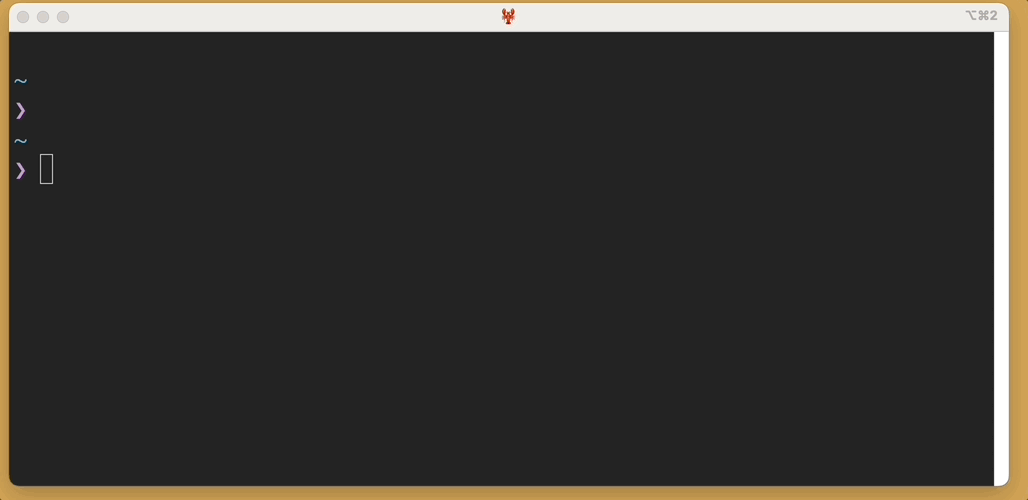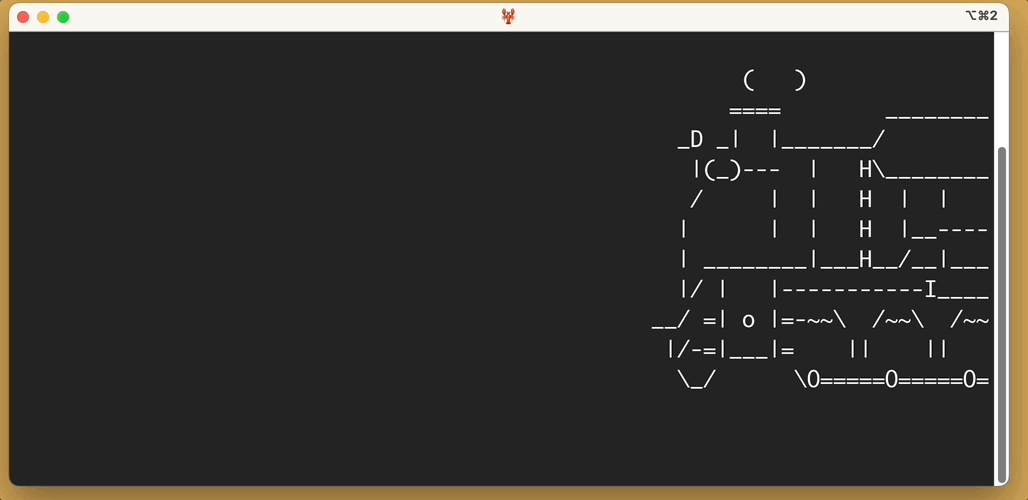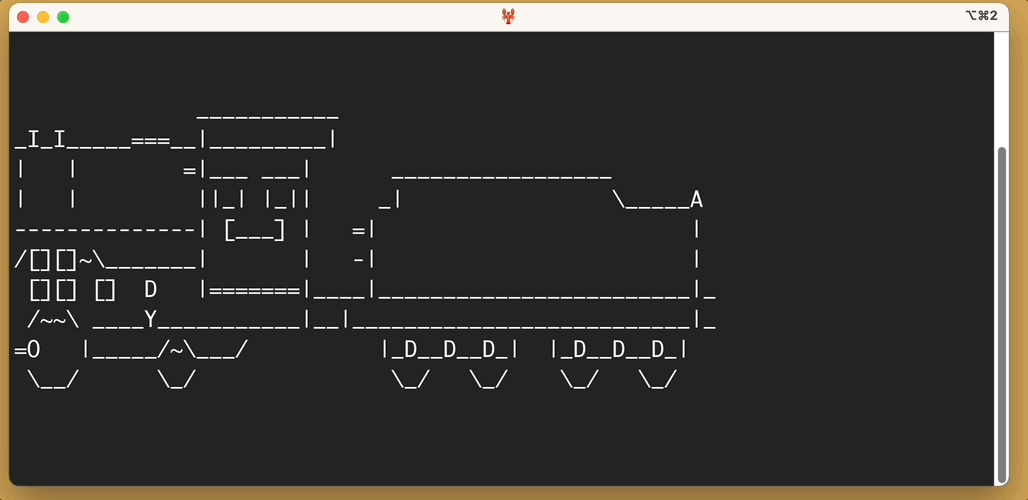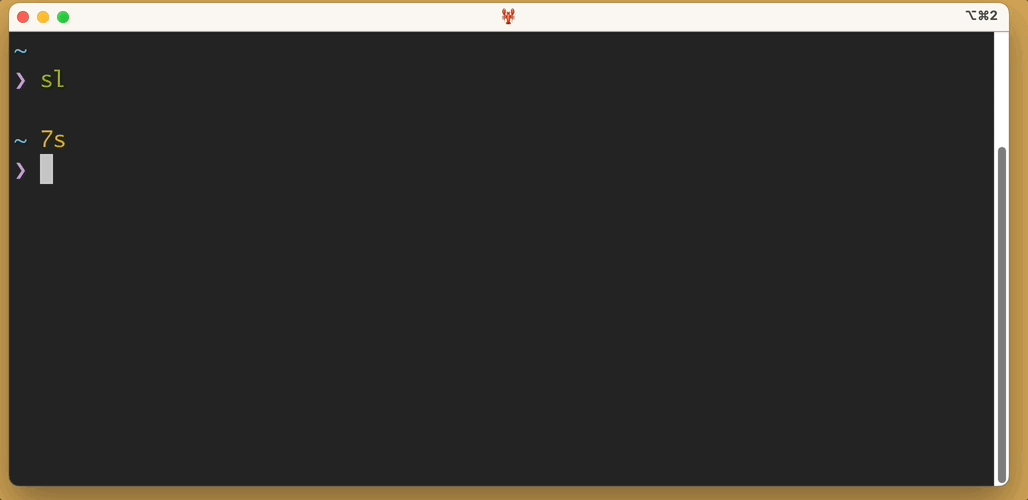
I’ll go into why this is very important, and in fact the remainder of this blog post is entirely about how much I love this command and what it means to me, so I apologize if you want to learn more about sapling. I literally cannot even try it, because I cannot install it, because of this naming collision. So you’re on your own. I hope it’s great.
Here’s the output of man sl, which has a lot to unpack:
SL(1) General Commands Manual SL(1)
NAME
sl - cure your bad habit of mistyping
SYNOPSIS
sl [ -alFc ]
DESCRIPTION
sl is a highly advanced animation program for curing your bad habit of
mistyping.
-a An accident is occurring. People cry for help.
-l Little version
-F It flies like the galaxy express 999.
-c C51 appears instead of D51.
SEE ALSO
ls(1)
BUGS
It sometimes lists directory contents.
AUTHOR
Toyoda Masashi (mtoyoda@acm.org)
March 31, 2014 SL(1)
First of all.. let’s check out some of these delightful alternate modes.
Here’s the output of sl -a:
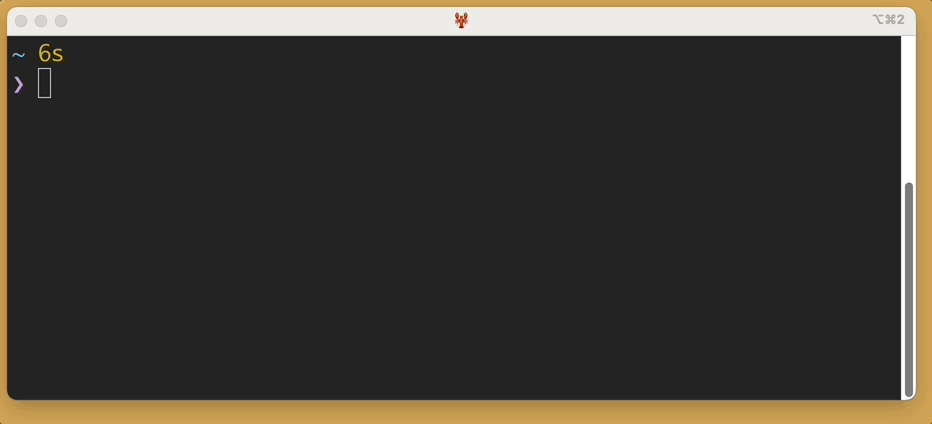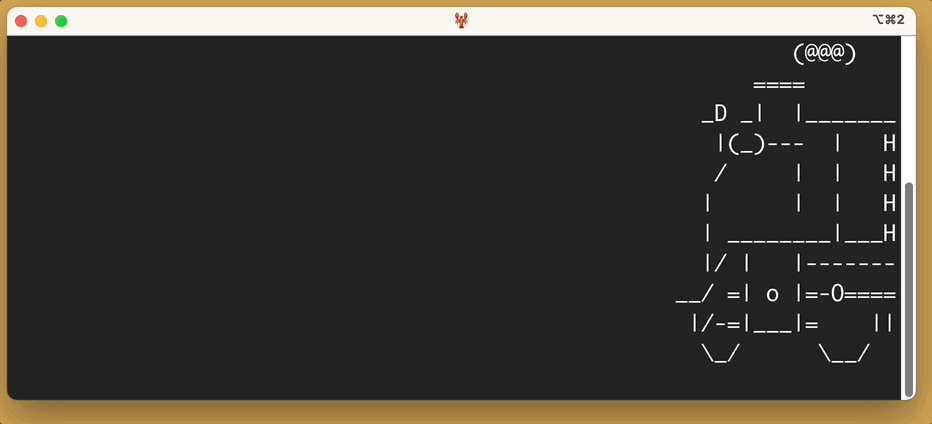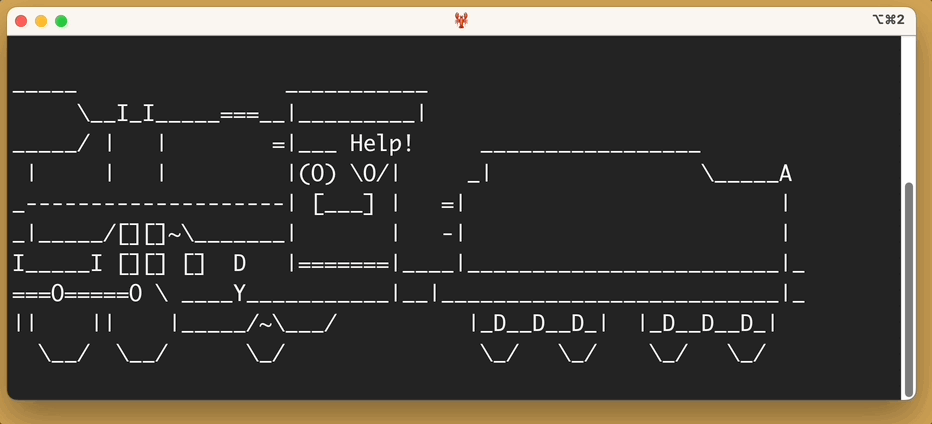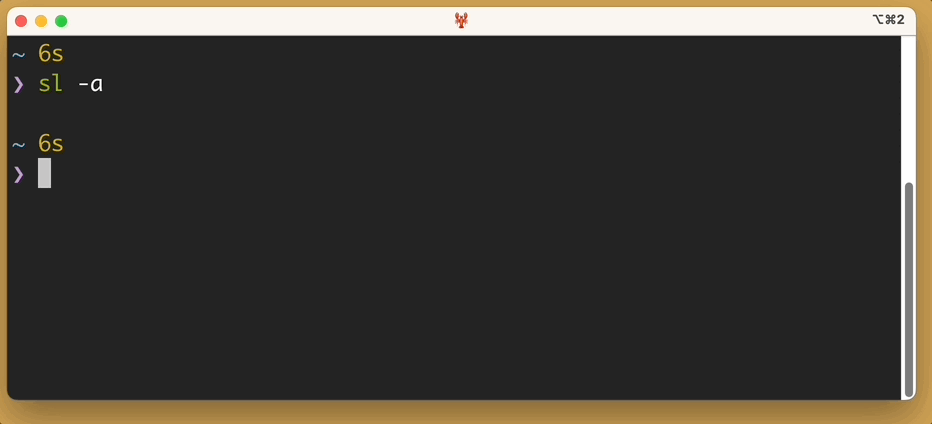
You’ll notice, as promised, that people cry for help.
There are a few other fun flags, but I’ll leave exploring those as an exercise for the reader. One tip: try combining flags.
Some fun facts about sl:
- Looking at the source code, it seems this program dates back to 1993, when this blog’s author was five years old.
sl, of course, is short for steam locomotive.- The author, Masashi Toyoda, is currently a professor at The University of Tokyo, but he still highlights his true claim to fame –
sl, of course – on his homepage - It takes about six seconds to run
- If you try to kill it by pressing ctrl c to send an interrupt signal, it just ignores you. This is very annoying in a peevish way that I find charming. You will sit through the animation.
The man page makes it sound like the motivation for this was to help break a habit of misstyping ls as sl.
If, each time you make that mistake, you’re forced to watch a 6 second animation that you cannot skip… perhaps that will help you break that habit.
This is kind of like the command line version of Mavala Stop Deterrent Nail Polish Treatment, a product I’ve personally found very helpful. You may have heard of it. It’s a clear nail polish you can put on which tastes terrible. If you find yourself idly biting your nails, it will help you stop. It’s incredibly helpful as a habit breaker.
I personally do not misstype ls as sl very often.
In fact I often will idly type sl on purpose and watch the train animation when I’m thinking thru a problem.
But I have found it useful to help break some other habits. I’ll give one more example.
One command line habit I have is running hub browse to open the current repo on github.com.
It’s great.
It’s context dependent, so for example if you’re currently on a branch, it will open that branch on github.com.
But I want to break this habit.
A few years ago, GitHub introduced an official CLI called gh.
I installed that too, and it’s also pretty good, and in fact it also has a command called gh browse.
Based on this doc comparing hub and gh, I would like to stop using hub entirely and just use gh.
There’s only two problems:
gh browsedoes not seem to be as clever ashub browse; it just loads the repo home page, no matter what branch you’re on- my damn muscle memory continues to type
hub browseno matter what I do
So… where does sl come in?
First step: uninstall hub with brew uninstall hub.
It’s gone now.
Nice.
Now when I type hub browse, I see this:
$ hub
zsh: command not found: hub
That’s accurate enough, but it’s not sufficiently punitive to be effective.
Second step: bring in the steam locomotive
I added this alias to my shell configuration:
alias 'hub'='sl -a'
Now, whenever I type hub browse… I get the train.
Third step: make gh browse context dependent.
Running man gh-browse, I see that gh browse actually has some handy-looking options:
OPTIONS
-b, --branch <string>
Select another branch by passing in the branch name
-c, --commit
Open the last commit
(plus some others, not pictured).
Which is to say that you can run gh browse --branch asdf to open github to branch asdf.
Or you can run gh browse --commit to browse directly to the last commit, wherever you’re currently checked out.
So, a script like this, built on top of the gh CLI, kinda-sorta recreates the behavior of hub browse:
#!/usr/bin/env sh
branch="$(git symbolic-ref --short HEAD 2>/dev/null)"
if [ $? -eq 0 ]; then
gh browse --branch="$branch"
else
gh browse --commit
fi
So, now we can save that file as git-browse, and put it somewhere on our $PATH.
Now I can type simply git browse and git will find that git-browse script and invoke it.
Under the hood, it uses the gh command.
And if I ever forget, and type hub browse, I get to look at a train and contemplate my choices.
-
I guess I should say “Meta” but idc ↩
-
Why, in GitHub Desktop, do you “publish” your branch instead of “push” it? I can see the argument that it’s more intuitive to a beginner, but it forces them to learn two things instead of one. ↩
-
In fact I made a little project called sapling 7 years ago which had nothing to do with git. It was a knock-off of tree another favorite tool of mine, that I made when I was first learning the basics of Rust. ↩
