I usually use rubocop to help maintain consistency and catch bugs in my Ruby codebases.
When I’m using Vim, I can see the feedback inline via Asynchronous Lint Engine, aka ALE, the terrific vim plugin.
Here’s what it looks like:
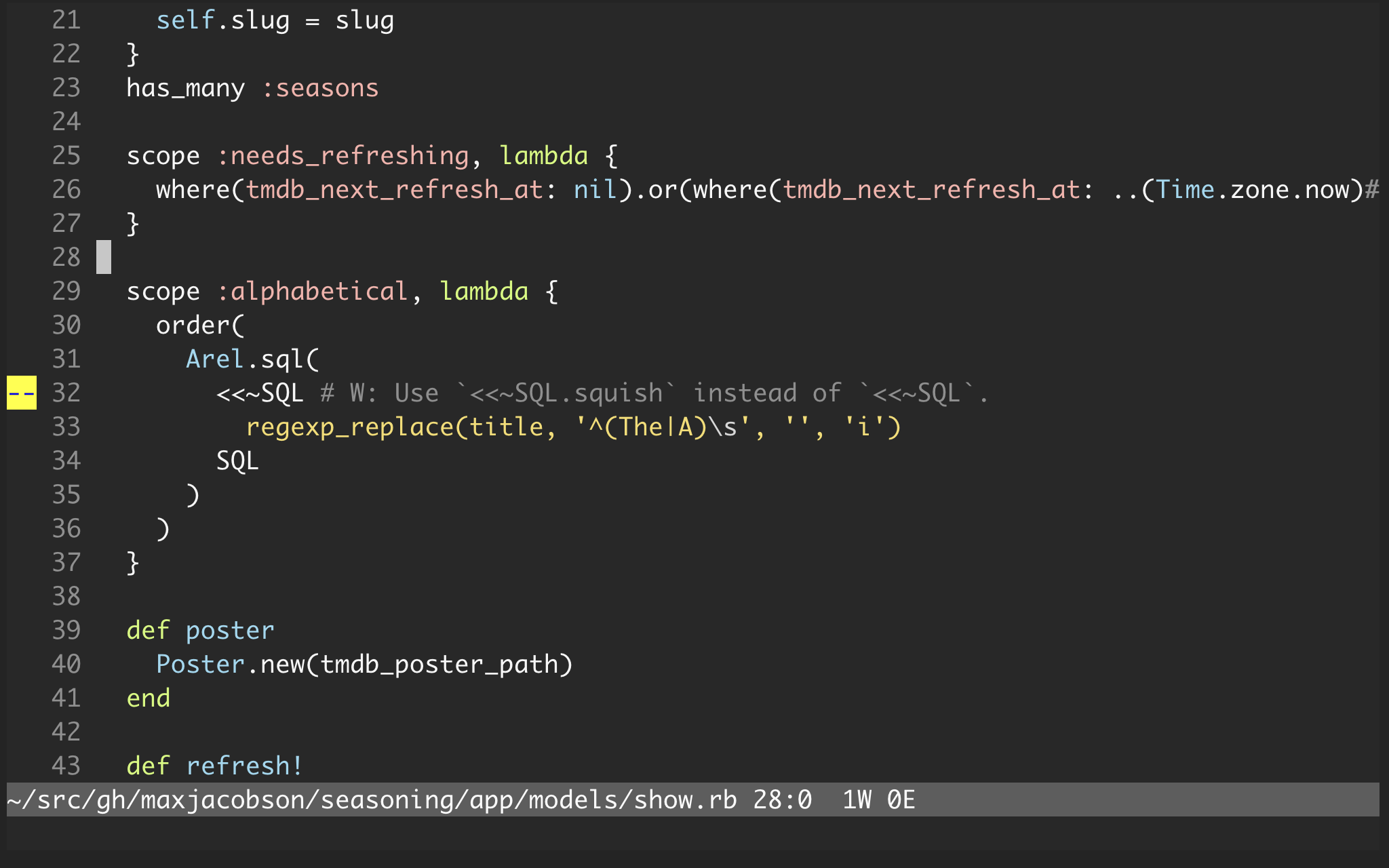
Nice!
I could run rubocop from the command line and see my offenses there, but it’s a really nice workflow to see the offense right away, in context, when I introduce it in the editor.
Before I used this vim plugin, I’d just run the rubocop CLI on the command line, which looks like this:
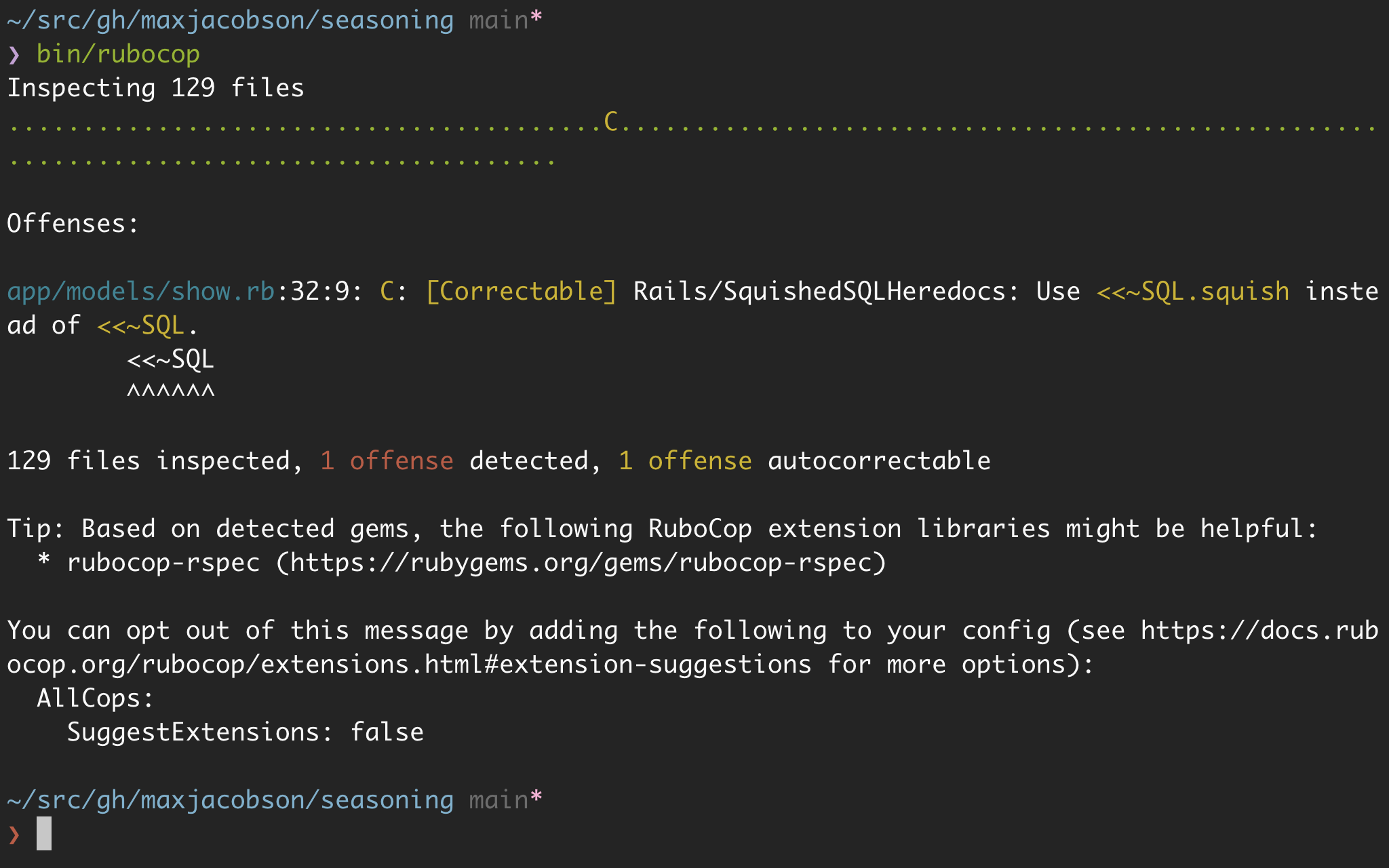
It’s clear enough what’s happening, but you’d need to open the file to see the context, and there’s some noise, so I think the editor integration is a real improvement.
But! There’s one problem… not every ruby codebase uses rubocop.
For example, the RSS reader I use, Feedbin, is an open source rails app, and when I clone it and open it in vim, here’s what I see:
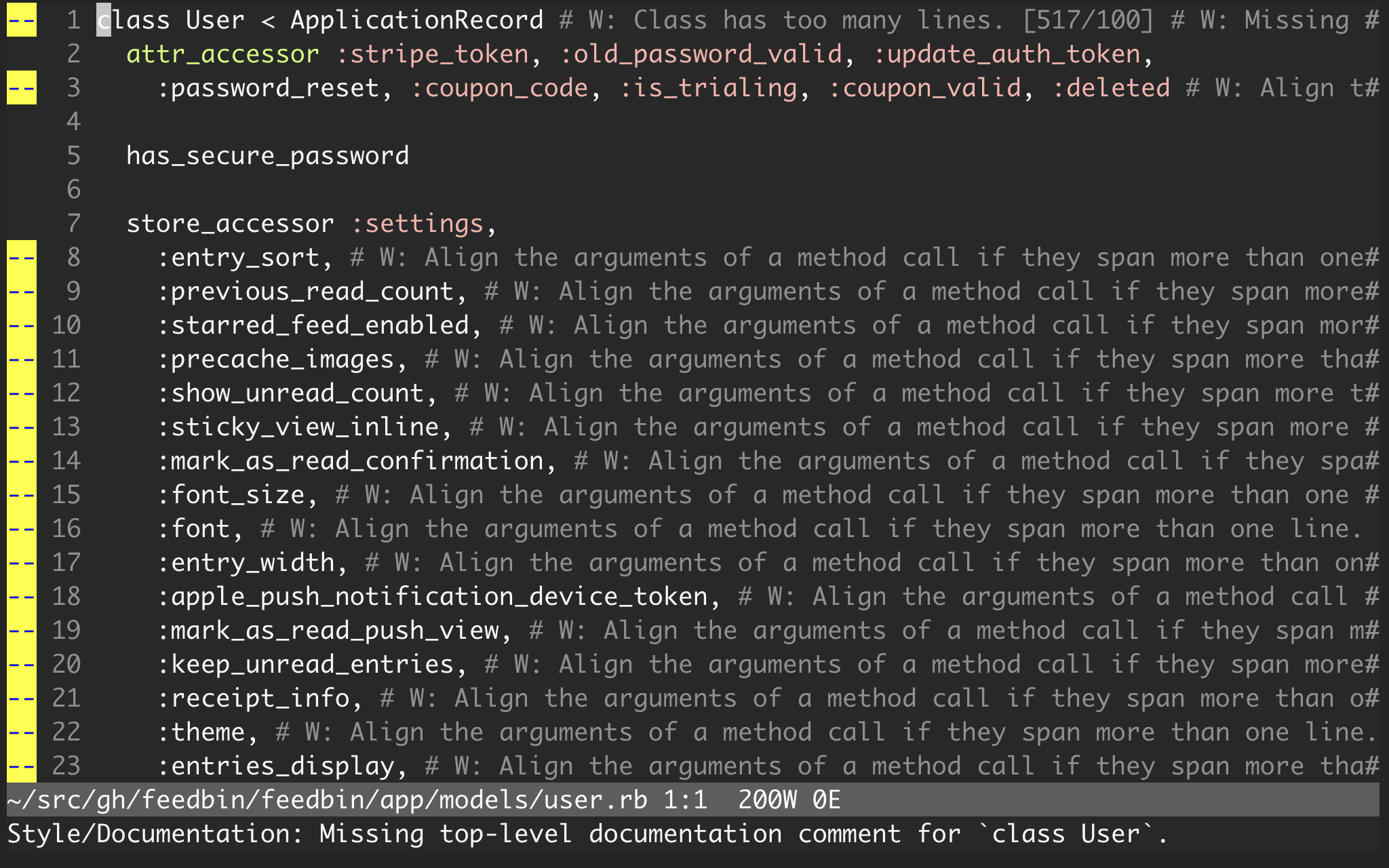
Yikes!!!
This codebase doesn’t even use rubocop, so of course there are a lot of “offenses”.
This is so annoying that it almost makes me want to disable ALE, but that would make my experience worse when I’m working on codebases that do use rubocop.
What to do?
Thankfully, after some poking around, I found out that it is possible to improve the situation with some ALE configuration. Here’s a bit about how I worked that out.
Here’s what I had in my .vimrc:
let g:ale_linters_explicit = 1
let g:ale_linters= {'ruby': ['rubocop']}
let g:ale_fixers = {'ruby': ['rubocop']}
let g:ale_ruby_rubocop_executable = "bundle"
let g:ale_fix_on_save = 1
I thought this would be sufficient.
I ran :help ale-ruby and read through the docs there, and found this relevant bit:
g:ale_ruby_rubocop_executable *g:ale_ruby_rubocop_executable*
*b:ale_ruby_rubocop_executable*
Type: |String|
Default: `'rubocop'`
Override the invoked rubocop binary. Set this to `'bundle'` to invoke
`'bundle` `exec` rubocop'.
So, because I configured that ale_ruby_rubocop_executable global variable to "bundle", that means that ALE is going to invoke bundle exec rubocop instead of simply rubocop.
That has a few nice benefits:
- You can feel confident that you’ll use the version of rubocop specified in your
Gemfile.lock - If rubocop is not included in your
Gemfile.lock, thebundle exec rubocopcommand will fail, and therefore no offenses will be found
So… wait a second, why was I seeing any rubocop offenses in the feedbin codebase if feedbin doesn’t use rubocop?
Hm, let’s try searching the codebase with ripgrep for references to rubocop:
$ rg rubocop
Gemfile.lock
517: rubocop (1.42.0)
524: rubocop-ast (>= 1.24.1, < 2.0)
527: rubocop-ast (1.24.1)
529: rubocop-performance (1.15.2)
530: rubocop (>= 1.7.0, < 2.0)
531: rubocop-ast (>= 0.4.0)
572: rubocop (= 1.42.0)
573: rubocop-performance (= 1.15.2)
Hmm, what the heck, rubocop is in the bundle, even though feedbin doesn’t actually use it. How is it getting in there?
If bundler had a subcommand like npm explain, we could use that to find out exactly why it’s in our bundle.
Alas, it doesn’t, so we must resort to reading through Gemfile.lock and figure it out.
If we look closely, we’ll see this clue:
standard (1.22.1)
language_server-protocol (~> 3.17.0.2)
rubocop (= 1.42.0)
rubocop-performance (= 1.15.2)
Aha! The feedbin codebase uses standard, which is kind of like an opinionated wrapper around rubocop.
So, because feedbin has this line its Gemfile:
gem "standard"
We get the standard gem and we also get its dependencies in the bundle, which includes rubocop.
That means that when ALE tries running bundle exec rubocop, rubocop will run.
If we take a look at standard’s docs, we can find a page about integrating standard with vim which recommends this:
The recommended method for running standardrb within vim is with vim-ale.
To set Standard as your only linter and fixer for Ruby files and thereby preventing conflicts with RuboCop, add these lines to your .vimrc file:
let g:ale_linters = {'ruby': ['standardrb']} let g:ale_fixers = {'ruby': ['standardrb']}For automatically fixing on save, add this to your .vimrc:
let g:ale_fix_on_save = 1
Nice! ALE also supports standard, and can be configured to use standard instead of rubocop.
But that’s not exactly what I want…
To recap, here are my goals:
- When working in a codebase that uses rubocop, I want ALE to use rubocop to lint and fix
- When working in a codebase that uses standard, I want ALE to use standard to lint and fix, and not use rubocop directly
- When working in a codebase that uses neither, I want ALE to do nothing
Thankfully, this can be achieved.
Here’s what we can do:
let g:ale_linters_explicit = 1
let g:ale_linters= {'ruby': ['rubocop', 'standardrb']}
let g:ale_fixers = {'ruby': ['rubocop', 'standardrb']}
let g:ale_ruby_rubocop_executable = "bin/rubocop"
let g:ale_ruby_standardrb_executable = "bin/standardrb"
let g:ale_fix_on_save = 1
We’re no longer setting ale_ruby_rubocop_executable to "bundle", because it proved to be insuffient in codebases like feedbin.
Now we’re configuring it to point to the rubocop binstub1. And likewise, we’re configuring it to point to the standard binstub. If a codebase has a binstub for a tool, that’s a pretty good sign that it uses that tool.
This way, ALE will use rubocop in a codebase that has a rubocop binstub and it will use standard in a codebase that has a standard binstub.
There should never be a codebase that has both binstubs2, so you don’t need to worry about activating both of them.
Just run bundle binstubs rubocop or bundle binstubs standard and commit the generated file and you’re good to go.
-
Of course it’s possible that both will be there if you run
bundle binstubs --alland commit them all, but… please do not do that! ↩